Problem
I have been on a job hunt for awhile now. While I want to be always want to show authenticy and be genuine through my resumes and cover letter by always catering it to a specific job description, it is also take quite a bit of time.
I was also going through the Coursera IBM course on "Fundamentals of AI Agents using RAG and Langchain", so I thought I should try applying the project from that course, to this use case. Using language models through the Langchain environment rather than just using it regularly online.
Initial Solution
At first, I thought that I would be improve the efficiency of the process. If it took me about a range of 15 mins - 30 mins to complete one resume and cover letter, I would need the solution to finish it in lesser time for me. Therefore, I should use a smaller LLM model as the task seems simple enough, and I need the LLM to fit whole into the GPU VRAM.
So, the first iteration was just a one ChatOllama instance, or a single LLM process, where I included the whole prompt which can be seen in the code below, asking it to look into the list of project experiences I have prepared, select whatever that is relevant to the job description, and paraphrase accordingly.
class CustomisedProjectExperiences(BaseModel):
customised_output: List[str] = Field(
"List of 4 to 6 customised project experiences"
)
def customise_project_experience(model, job_description, project_experience_list):
system_instruction = (
"You are a top analytic recruiter. You are a resume writer. Your goal is to customise the given project experiences for a given job description.\n"
"CONSTRAINTS:\n"
"1. NO RANDOM ADDITION: Do not add skills, statements, tools, languages, or impacts that were not in the list of project experiences.\n"
"2. WORD COUNT: Exactly 30 - 80 words per project selected.\n"
"3. INTEGRITY: Tailor the language to the job, but never change the facts.\n"
"4. SOURCE OF TRUTH: Only use what is given in the list of project experiences."
)
user_instruction = (
"Job Description: {job_description}\nProjects Experiences: {project_experiences}\n"
"TASK:\n"
"1. Select 4 to 6 projects most relevant to the job description\n"
"2. Rephrase the selected project description, and/or the project title (if required) truthfully without lying to highlight most relevant experiences for the job description, while retaining the core project descriptions.\n"
"3. It should be slightly catered and customized towards the specific job description, in 30 - 80 words for each project selected.\n\n"
"4. Remember the constraints that were listed."
)
prompt = ChatPromptTemplate.from_messages([
("system", system_instruction),
("user", user_instruction)
])
input = {
"job_description": job_description,
"project_experience_lists": project_experience_lists
}
chain = prompt | model.with_structured_output(CustomisedProjectExperiences)
response = chain.invoke(
input=input
)
return responseThis turned out not as well as expected. I was not using any frontier models at this point. I was testing the waters with Gemma 3:12b, gpt-oss-20b, qwen3.5:9b and a few more small open weight models. I am also running these in 'Q4_K_M' quantization as there are memory constraints, and this quantization is also the Ollama's default when pulling the models. The output were extremely inconsistent. Some times it would generate something decent but it would usually hallucinate quite a number of non-existent skills or impacts, and it usually oversells based on the job descriptions.
Next Iteration: Breaking things down
I am not sure if I am overestimating the abilities of these LLMs, but I was expecting them to be able to do this in one go. Since this is not the case, I then tried to break it down into smaller, more manageable tasks.
I made it where the first task was to only pick out the project ID of the 6 most relevant project to the job description. Then, I filter for only the select projects from the original project list. Finally, I would feed this filtered list and the job description again for the model to paraphrase.
class SelectedProjects(BaseModel):
selected_ids: List[str] = Field(
description=(
"List of 6 project IDs most relevant to the job."
"MUST be in the exact format 'proj_XXX' (example: 'proj_001', 'proj_012'). Do not write titles, only IDs."
)
)
def select_projects(model, job_description, project_experience_lists):
# Using .bind so that it does not globally set the parameters for the original/global instance
# Setting lower temperature as this is a stricter tasks. Does not require creativity.
# Setting the repeat penalty to ensure thinking models do not loop infinitely
model_config = model.bind(
temperature=0.2,
)
# Prompt Setup
system_instruction = (
"You are a top analytical recruiter. Read the list of project experiences and job description."
"Select exactly 6 Project IDs that matches the job description as close as possible."
"CRITICAL: You MUST output the exact project_id string (e.g., 'proj_001', 'proj_012')."
"Do not change the casing, add spaces, or invent IDs."
)
user_instruction = "Job Description: {job_description}\nProjects Experiences: {project_experience_lists}"
prompt = ChatPromptTemplate.from_messages([
("system", system_instruction),
("user", user_instruction)
])
input = {
"job_description": job_description,
"project_experience_lists": project_experience_lists
}
# Run the model
chain = prompt | model_config.with_structured_output(SelectedProjects)
response = chain.invoke(
input=input
)
# Outputs a list of project IDs
return response
class CustomisedProject(BaseModel):
project_id: str = Field(description="Project ID - DO NOT change this.")
project_title: str = Field(description="Project Title - change this only if necessary")
project_description: str = Field(description="Project Description - edited project description")
class CustomisedListOfProjects(BaseModel):
list_of_projects: List[CustomisedProject] = Field(description="List of customised project experiences")
def customiseSelectedProjects(model, job_description, project_experiences):
# Using .bind so that it does not globally set the parameters for the original/global instance
# Setting medium temperature as it requires a little creativity. To avoid hallucination, we will not be setting it to 1.
# Setting the repeat penalty to ensure thinking models do not loop infinitely
model_config = model.bind(
temperature=0.5
)
# Prompt Setup
system_instruction = (
"You are a resume writer. Your goal is to customise the given project experiences for a given job description.\n"
"CONSTRAINTS:\n"
"1. NO RANDOM ADDITION: Do not add skills, statements, tools, languages, or impacts that were not in the list of project experiences.\n"
"2. WORD COUNT: Exactly 30 - 80 words per project selected.\n"
"3. INTEGRITY: Tailor the language to the job, but never change the facts.\n"
"4. PROJECT IDs: Do not change the project id. Directly use the one from source. If the source project id is 'proj_001', use 'proj_001'. Do not make up your own.\n"
"5. SOURCE OF TRUTH: Only use what is given in the list of project experiences."
)
user_instruction = (
"Job Description: {job_description}\nProjects Experiences: {project_experiences}\n"
"TASK:\n"
"1. Rephrase the selected 6 project description, and/or the project title (if required) truthfully without lying to highlight most relevant experiences for the job description, while retaining the core project descriptions.\n"
"2. It should be slightly catered and customized towards the specific job description, in 30 - 80 words for each project selected.\n\n"
"3. Remember the constraints that were listed."
)
prompt = ChatPromptTemplate.from_messages([
("system", system_instruction),
("user", user_instruction)
])
input = {
"job_description": job_description,
"project_experiences": project_experiences
}
# Run the model
chain = prompt | model_config.with_structured_output(CustomisedListOfProjects)
response = chain.invoke(
input=input
)
# Outputs a list of customised project experiences
return responseBy splitting the tasks into two this way, it helps the model focus on one thing at a time. This also allows the model to utilise its context window more efficiently as it is only dealing with a subset of the projects. This is much more effective as it drastically reduces the chance of hallucination.
Hallucination persisted
However, there were a few models that still hallucinate even after splitting the tasks into two. Ministral3:14b and qwen3.5:9b are two such models that hallucinate quite often. Qwen3.5:9b not only hallucinates but also takes a very long time to process. This might be because it is a 'thinking' model. Later we will see this trend when comparing them to other models too. The Qwen3.5:9b was such a hyped up open weight model online, and it was surprising to see that it hallucinates so much, even with default settings or even with lower temperature settings, as I have set 0.2 for selecting projects, and 0.5 for customising the selected projects. Examples of hallucination are changing the project id into different formats and over catering to the job description, like completely basing the project experience from the job description, rather than the list I have provided. There is one instance of the test, where instead of customising 6 project experiences, it generated 100 made up project experiences.
Measuring Runtime and subjectively evaluating the Generated Output
Then, I performed a simple test, running 11 iterations for each model. I have selected a mix of models from Qwen, Deepseek, Mistral, Google and OpenAI. There are dense models and Mixture-of-Experts (MoE) models as well.
In each iteration, I called the select_projects function followed by the customiseSelectedProjects function. I recorded the time taken for each function call and performed a subjective quality check on the generated output. The goal was to identify which models performed best in terms of both speed and output quality.
I tested this after the release of Gemma 4, which was exciting having an update to Gemma 3.
| Model | Total Rounds | Successes | Failures | Success Rate |
|---|---|---|---|---|
| qwen3.5:9b | 11 | 7 | 4 | 63.64% |
| llama3.1:8b | 11 | 11 | 0 | 100.00% |
| mistral-nemo:12b | 11 | 11 | 0 | 100.00% |
| gpt-oss:20b | 11 | 11 | 0 | 100.00% |
| gemma3:12b | 11 | 11 | 0 | 100.00% |
| gemma4:e4b | 11 | 11 | 0 | 100.00% |
| deepseek-r1:8b | 11 | 11 | 0 | 100.00% |
| deepseek-r1:14b | 11 | 11 | 0 | 100.00% |
We can see that qwen3.5:9b hallucinated 4 out of 11 times, while others performed perfectly, and this is only the selection process. It might be the task is too simple that does not require a thinking model.
Selection Process
Selection Process Runtime
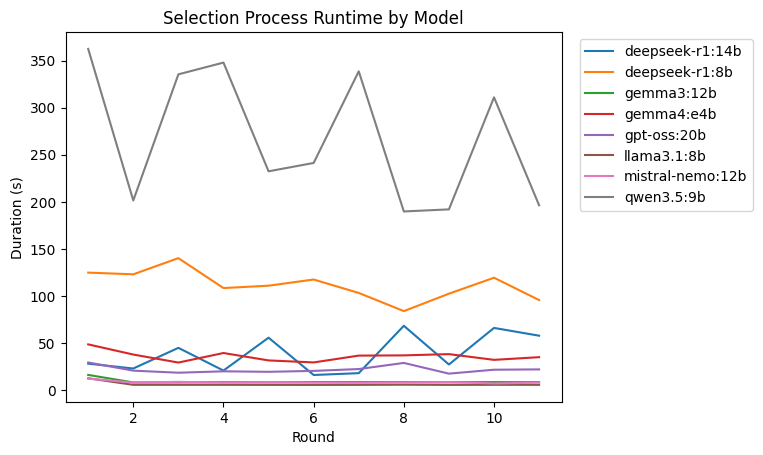
Based on the plot, we can see how consistent is each model in terms of the variation of runtime, and how fast is each model in terms of the mean runtime. We can see that qwen3.5:9b not only is the slowest model, it is also the most inconsistent model, with a very big standard deviation and range. Then, we can also see the deepseek models have also a wider range than the other models.
Selection Process Runtime Table
| model | mean | std | min | max |
|---|---|---|---|---|
| deepseek-r1:14b | 38.81 | 20.17 | 16.16 | 68.42 |
| deepseek-r1:8b | 111.83 | 15.49 | 83.99 | 140.24 |
| gemma3:12b | 9.21 | 2.33 | 8.27 | 16.25 |
| gemma4:e4b | 35.99 | 5.50 | 29.36 | 48.67 |
| gpt-oss:20b | 21.99 | 3.85 | 17.61 | 29.45 |
| llama3.1:8b | 6.34 | 2.09 | 5.62 | 12.66 |
| mistral-nemo:12b | 8.52 | 1.34 | 7.22 | 12.38 |
| qwen3.5:9b | 268.06 | 70.77 | 189.81 | 362.38 |
We can see that llama3.1:8b and mistral-nemo:12b are the fastest, while qwen3.5:9b is significantly slower than the rest. Theorictically, the qwen3.5:9b is supposed to be relatively faster because of the Gated DeltaNet implementation which turns a quadratic formulation in the attention mechanism to a linear one, maintaining efficiency regardless of the context length. However, it is surprising to see that it is the slowest among all the models, as it might due to the model's looping during its chain-of-thought or reasoning process.
Also, we can see that the deepseek-r1:14b model is faster than the deepseek-r1:8b model. This is surprising as it is a larger model. We can infer that maybe because the 14b has more parameters, which allows it to be 'smarter' with the selection process, requiring lesser tokens to solve the problem.
It is also surprising to see the large processing time difference between the deepseek-r1:8b and llama3.1:8b, because the former is distilled from the latter. With the reasoning built-in, it increases the processing time. This is also seen with the gemma3 vs gemma4. Because the gemma4 has reasoning or thinking capabilities, and it increases the processing time as well.
Customisation Process Runtime
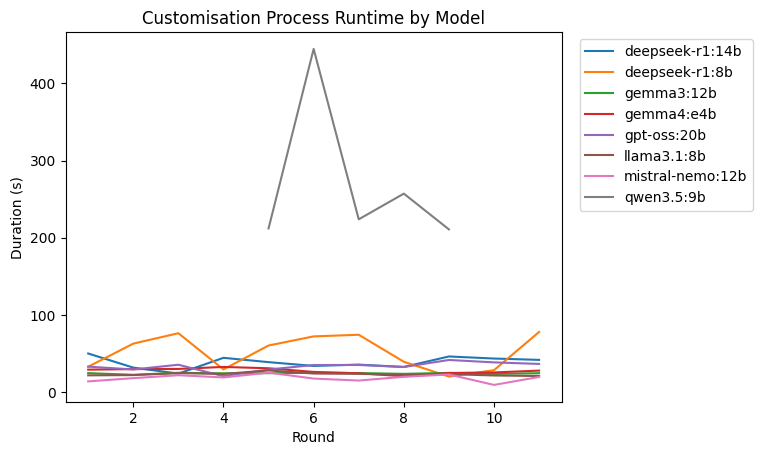
In this plot, it is harder for us to see the difference between the models, because of the qwen3.5:9b's duration being so much longer than the rest. Let me remove it and plot it again.
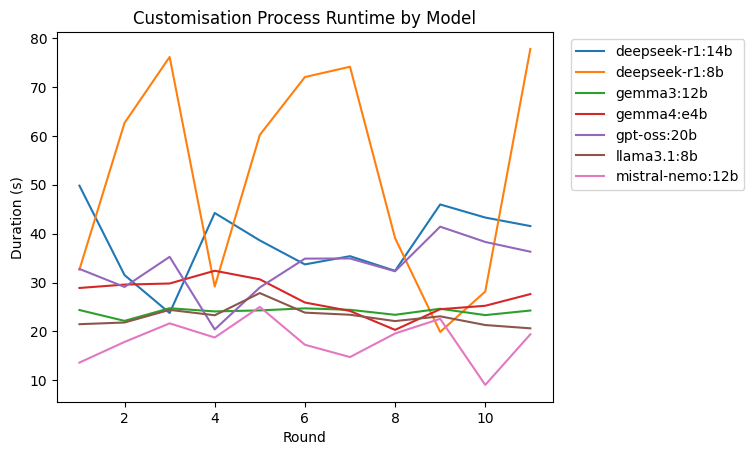
Based on the plot we can see that it is a closer comparison than the one in the selection process. We can see that mistral-nemo:12b is the fastest model in this process. Then, llama3.1:8b, and gemma3:12b being close with each other in terms of spped and consistency. Followed by gemma4:e4b, gpt-oss:20b, and deepseek-r1:14b. The deepseek-r1:8b model can be fast but also really slow, having the biggest range among the remaining models.
Customisation Process Runtime Table
| model | mean | std | min | max |
|---|---|---|---|---|
| deepseek-r1:14b | 38.20 | 7.63 | 23.77 | 49.80 |
| deepseek-r1:8b | 51.98 | 22.30 | 19.90 | 77.76 |
| gemma3:12b | 24.05 | 0.78 | 22.16 | 24.75 |
| gemma4:e4b | 27.20 | 3.51 | 20.32 | 32.41 |
| gpt-oss:20b | 33.15 | 5.58 | 20.41 | 41.42 |
| llama3.1:8b | 23.03 | 1.98 | 20.64 | 27.85 |
| mistral-nemo:12b | 18.15 | 4.45 | 9.07 | 25.02 |
| qwen3.5:9b | 252.66 | 87.36 | 187.72 | 444.77 |
Generated Output Review
Each model is supposed to generate 6 project experiences, there are 11 iterations and 8 models. So I decided to just subjectively random sample few outputs from each model and see if the generated output is satisfactory for this given use case.
Qwen3.5:9b
For the qwen3.5:9b model, when it does not hallucinate, it does have very good output. However, when it does, it completely customises the output for the job description, without using any source materials. For example, I haven't got any experience in Customer Engagement and E-Commerce Optimization experience, but it generated an experience for it. With it processing so slow, and hallucinating so often, it is not a good candidate for this use case.
Llama3.1:8b
For the llama3.1:8b model, it is very fast, and it does not hallucinate as well. Based on my review of the few outputs, it seems to perform very well for this use case.
Mistral-nemo:12b
As for the mistral-nemo:12b model, there were instances of the output where it only selected lesser than 6 projects, which could explain it faster runtimes. However, the generated output are accurate enough as well. It does not have severe hallucination like the qwen3.5:9b model, but it has some instance of over summarizing the content, where the content of the project experiences has been slightly altered or being not clear enough.
Gpt-oss:20b
For gpt-oss:20b, it is relatively fast, consistent and accurate. Its outputs are good and consistently selects 6 projects as well. Same can be said for the gemma3 model as well.
Gemma4:e4b
However, for the gemma4, it has instances where it does not select enough projects, similar to mistral-nemo, and it also has some hallucination issues, not as severe as qwen3.5, but it does happened.
Deepseek-r1:14b
Lastly, for the deepseek models. The deepseek-r1:14b is relatively fast but can also be slow at times, consistent and accurate, but there were instances of selecting less than 6 projects as well. The deepseek-r1:8b outputs are good with very little to no hallucinations, but because of its longer processing time, I will likely not continue with this model.
New Problem
When performing the generated output review, if I were to run this process again, with 10 job descriptions, even with 4 models selected, that would be about 240 project experiences I need to review and vet through. It would be time consuming and tedious to do it manually. Therefore, I need a way to automate or a way to filter the outputs of this process, which got me thinking.
Another Iteration: Auditor / Checker Models
The next idea I had, was to use bigger models as a 'judge', 'auditor' or 'checker' to perform the review process, and selecting the best one among all the outputs. The models I selected are as follows:
- deepseek-r1:32b
- nemotron-3-nano:30b
- nemotron-cascade-2:30b
- gemma4:31b
- gemma4:26b
- glm-4.7-flash
- mistral-small3.2:24b
- qwen3.6:27b
- qwen3.5:27b
All of these models are quantized models at 'Q4_K_M', to be able to fit into a 24g VRAM graphics card.
Test Cases
To test out the performances of these models, I have created 10 test project experiences from a base version. Version 1 to 10. Version 1 to 5 are just shorten version of the previous one. So version 1 shorten from the base version, and the version 2 is a shorten version of version 1, and so on.
Version 6 to 10 are deliberately altered. Version 6 and 7 are based on version 5, but version 6 has numeric values changed, like 10 samples changed to 20 samples, 1400 participants changed to 200 particiapnts.
Version 7 is based on version 5, but the methods used in the projects are changed. Instead of kNN, I replace it with BsG or some random made up methodology.
Version 8 is based on version 3, but it has additions of not truthful statements.
Version 9 and 10 is based on version 3 and 5 respectively, but with instructions to make it 'impactful' using frontier Google Gemini. When read, version 9 has clearly made impact statement that oversells the project experiences I have, but version 10 is a little bit more ambigious, it maintains original meaning but the additional impact statement are subtle.
While version 9 and 10 are not fully wrong in terms of content, I would like to see what the larger models decide or justify the passing or failing of version 9 and 10. My preference is for the models to identify version 9 and 10 as 'false'.
The following is the code for the 'auditor' models.
We ask the model to check if the generated outputs are different from the source. It should check for its truthfulness, hallucination, and describe reasons for its decisions.
class CustomisedProjectAuditResult(BaseModel):
is_truthful: bool = Field(description="True if every claim in the tailored version is present in the source.")
has_hallucinations: List[str] = Field(description="Specific tools, skills, experience, statements or claims found in the tailored version that are NOT in the source.")
has_pass: bool = Field(description="Final result: True if it is truthful AND Hallucinations is empty.")
reasons: str = Field(description="A brief explanation of why it passed or failed.")
def audit_tailored_projects(model, generated_output, source):
prompt = ChatPromptTemplate.from_messages([
("system", "You are very strict inspector, auditor, and a reviewer. You are going to compare a list of generated outputs and its source, to identify errors in the generated output."),
("user",
"""There will several generated outputs provided.
1. Identify where in the source, is the generated output is from.
2. Once it is found, compare the generated output and its source for:
- Truthfulness: How truthful is the generated output compared to its source, is the core meaning of the source still understandable in the generated output
- Hallucination: How much added content is there in the generated output that is not in the source. There should be none. There should be NO ADDED CONTENT that are not truthful. For example, if the source states "Able to achieve accuracy of 70 percent by using model A.", and the generated output states "Able to achieved accuracy of 75 percent by using model B, which has caused an improvement and increased efficiency in the process". The generated output has mistakenly mentioned increased percentages, identified wrong model from the source, and also mistakenly added impact statements in the end of the generated output, that are not truthful from the source.
3. Based on your review, if the generated content is truthful and has no hallucination, then give it a pass. If not, it will fail the audit.
IMPORTANT: If there are any additional tool, experience, skill, impact or any statement mentioned in the generated output that is not truthful or in the source. The audit should fail.
Source: {source}
Generated Output: {generated_output}
""")
])
input = {
"source": source,
"generated_output": generated_output
}
chain = prompt | model.with_structured_output(CustomisedProjectAuditResult)
response = chain.invoke(input=input)
return responseRuntime Comparison for Auditor Models
Here is the boxplot for the runtimes of 10 test run for each model.
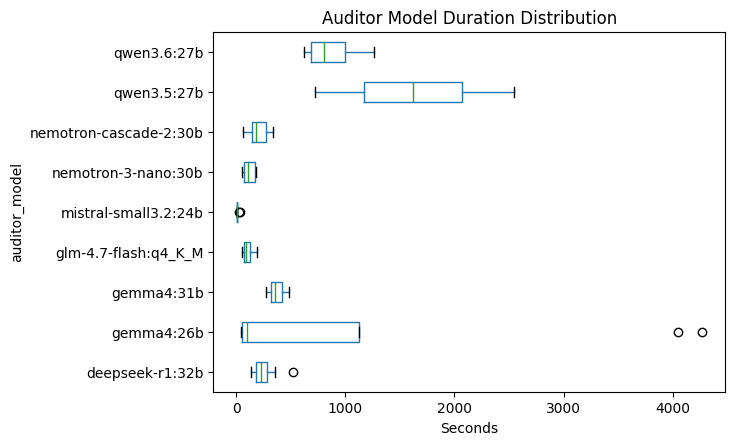
We can observe that the qwen3.5:27b, qwen3.6:27b and gemma4:26b are the slower models, and qwen3.5:27b can take very wide range of time to complete the task. It can take 723 seconds (12 minutes) to as long as 2549 seconds (42 minutes). As for gemma4:26b, it can go as fast as less than 50 secs to complete the tasks, but can also go as long as 4270 seconds (71 minutes). This is due to the hallucinations and thinking loops it can get into. We will discuss its generated output in a bit.
For the rest of the models, they look faster due to the 3 models above, so we will remove them and have a better look.
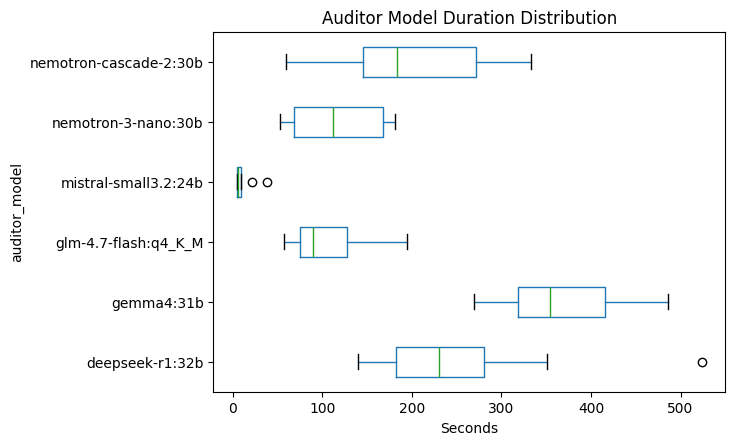
Based on this new plot, in a range of up to 500 seconds (8 minutes and 20 seconds), the fastest model seems to be minstral-small3.2:24b, similar to mistral-nemo:12b dominating in terms of speed. Even it's outliers from the boxplot are still faster than all models. Then next is nemotron-3-nano:30b and glm-4.7-flash, they are quite close to each other but opposing properties. The nemotron-3-nano:30b while overall slower, based on its median, but it is always consistent with the range of 70s to 165s, while the glm-4.7-flash ranges 75s to 125s more consistently, but might be prone to longer rumtimes based on the long right wick as seen in the box plot.
As for the nemotron-cascade-2:30b, and deepseek-r1:32b, they are also quite similar to each other, having a median of around 180 to 220 seconds, about 3 to 4 minutes to complete a task. Depending on the quality of the output, it might justify the extra time it takes to complete a task. But deepseek-r1:32b has an outlier with a runtime of 524 seconds (8 minutes).
Reviewing the Audits' Passing Rate
All the models were able to identify that test version 1 to 5 are the same as the source. But for version 6 until 10, the following are the results.
Incomplete attempts
Based on the result, we can see that gemma4:26b have not completed version 7 and 8 likely due to hallucinations and being stuck in a thinking loop.
Surprisingly, the glm-4.7-flash model did not finish version 8 as well.
Passing or Failing audits
We also can see that qwen3.5:27b passing the version 6 and 7, when both were the obvious lies and incorrent statement, that were easier to highlight.
All models failed test version 8. But for version 9 and 10, there are a variety of outputs from the models.
Firstly, mistral-small3.2:24b not only finished fast, but manages to fail both test version 9 and version 10 as being different from the source. The next two models that manages to fail both test version 9 and version 10 are qwen3.5:27b and qwen3.6:27b. However, these two model take too long to complete the task.
Both, deepseek-r1:32b and glm-4.7-flash:q4_K_M passed version 9 and 10, while both gemma models pass the version 9 but failed version 10. Both the nemotron models failed version 10 but surprisingly pass version 9.
Results are all over the place and surprising. Based on my perferences stated earlier, where I would likely prefer if the model failed version 9 and 10, but there are only 3 models that do so, (mistral-small3.2:24b, qwen3.5:27b and qwen3.6:27b). So the next best options are those that at least failed version 9, (gemma4:26b, gemma4:31b). However, these shortlisted models, two of them (gemma4:26b and qwen3.5:27b) have strong hallucination or looping issues. Then, gemma4:31b and qwen3.6:27b are the slow to finish the tasks, especially qwen3.6:27b.
Hence, none of the models are perfect and all have their own pros and cons. Only mistral-small3.2:24b seems to have no issues, but we will look at their audited outputs to see if we can further narrow down the options.
Reviewing the Audited Outputs
Gemma4:26b - The Problematic Output Loops
For gemma4:26b, it has the longest runtime with due to its hallucination and loops. I have saved the audited outputs for all models, and can be viewed in this file. It loops as it gets stuck on certain words or phrases, then repeats it for a very long time. It was so bad that for test 7 and 8, the model has run for over an hour before it was terminated. Based on the results csv file, it skipped from test 6 to test 9, and based on the difference in timestamp of test 6 and 9, 04:33:08 and 06:53:19 respectively, the difference between the two timestamps is approximately 2 hours 20 minutes. Test 6 only took 48 seconds to complete, so the timestamp while it is for the start of the process, the result is negligible.
Gemma4:31b - Not as Perfect as it Seems
When reviewing its why it has given a pass for test version 10, I noticed that in version 9 where it gave it a fail, it manages to identify issues with it, but in the 'is_truthful' column, it gave it a 'true' for some reason. Making it a little less reliable and afaid when used later, it would be hallucinating.
Qwen3.5:27b - One Small Screw-up
When reviewing the output, looking into its reasoning for passing obvious test on version 6 and 7, it actually identified all the hallucinations, errors or wrongful statements, and even listed them. But it still marked them as pass, which is weird. Even the column 'is_truthful' was 'False'. But either way, it runs really long so this model will likely not be used for this use case.
The Nemotrons
These seem to be the more balanced models in terms of speed and output. However, both the models gave version 9 a pass where the impact statements were more exxagerated, while giving version 10 a fail, which had impact statements that were more subtle. Both models noted that all generated descriptions in version 9 was accurate to its corresponding source document, while for version 10, it nitpicked on a phrase, and failed version 10.
Mistral-small3.2:24b - THE BEST OPTION SO FAR
As the fastest model, it also managed to fail test version 9 and 10 as 'False'. When reviewing the output, it seems to be one of the most reliable. But it also seemed very strict. In the test for version 6 to 9, it listed and identified areas where it captures the hallucinations, wrongful statements and errors. But for version 10, it only had one statement for the reason for failure, which is "The generated output has mistakenly mentioned high accuracy, which is not truthful from the source.". While it is good that it identifies the inaccuracies, but it can be very strict and trigger a fail for something that is not a big deal for our use case. We will keep this in mind for later.
Current Iteration
I have set up a pipeline where I manually look for jobs. Then, I will have a list of job descriptions in a csv file. This would be loaded into the worker models to be processed, currently using mistral-small3.2:24b, llama3.1:8b and gpt-oss:20b as the worker model to generated several versions. Then, it will be checked by 2 auditor models, mistral-small3.2:24b and gemma4:31b.
I have used Gemini to create a streamlit interface for reviewing the generated outputs for those that have at least one audit pass, for final manual approval, the approved ones will be used to generate the resume.
The process is called HITL or Human-in-the-loop, before allowing it to be fully automated, I will need to observe this process for a while to see if I can further improve the pipeline to reduce the need for human intervention.
Future Implementation
The next iteration, I will try to look into the following:
- Web scraping to get job descriptions
- Make this into an agentic process
- Have lesser involvement in reviewing the outputs