Tagged classification
Projects and posts related to classification.
python
10
machine-learning
6
finance
6
data-analysis
5
pandas
5
data-visualization
3
data-science
3
matplotlib
2
seaborn
2
scikit-learn
2
forecasting
2
big-data
2
self-hosting
2
virtualization
2
proxmox
2
clustering
1
classification
1
numpy
1
web-scrape
1
time-series-analysis
1
investment-strategies
1
bayesian-network
1
decision-support-system
1
financial-modelling
1
time-series
1
statsmodels
1
monte-carlo-sim
1
mapreduce
1
apache-mahout
1
image-classification
1
pyspark
1
decision-tree-classifier
1
random-forest-classifier
1
multilayer-perceptron
1
lstm
1
tensorflow
1
keras
1
technology-risk-management
1
audit
1
compliance
1
ubuntu
1
debian
1
web-development
1
html
1
css
1
javascript
1
eleventy
1
ai
1
langchain
1
ollama
1
large-language-model
1
financial-analysis
0
vba
0
excel
0
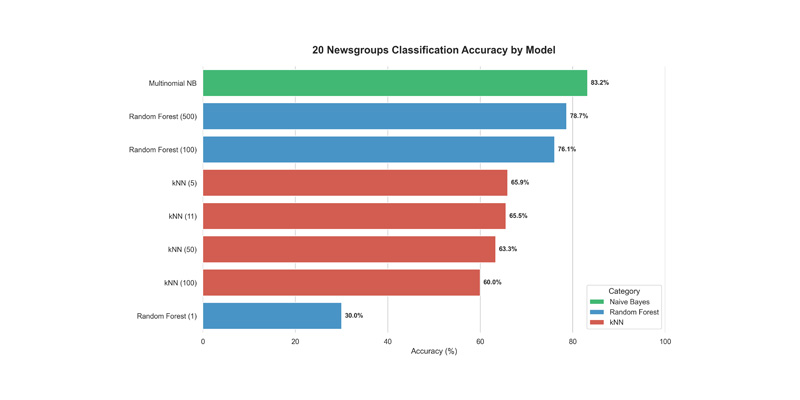
Supervised Learning Benchmarks for Numeric and Textual Data
Sep 18, 2023
machine-learning scikit-learn data-visualization classificationThis project conducts a detailed evaluation of popular machine learning algorithms and their performance characteristics. It benchmarks Naive Bayes, Random Forest, and k Nearest Neighbors across multiple datasets ranging from simple iris data to complex geospatial and text categories. The analysis explores the relationship between hyperparameter tuning and model efficiency while providing quantitative results on accuracy and execution time.