Projects & Blogs
A collection of my thoughts, experience, past and current projects.
Investment Strategy Comparison - Buy and Hold versus Dollar Cost Averaging
Mar 18, 2024
python data-analysis finance investment-strategiesAn exploration into traditional investment strategies, comparing the performance of 'Buy and Hold' and 'Dollar Cost Averaging' across volatile stock datasets.
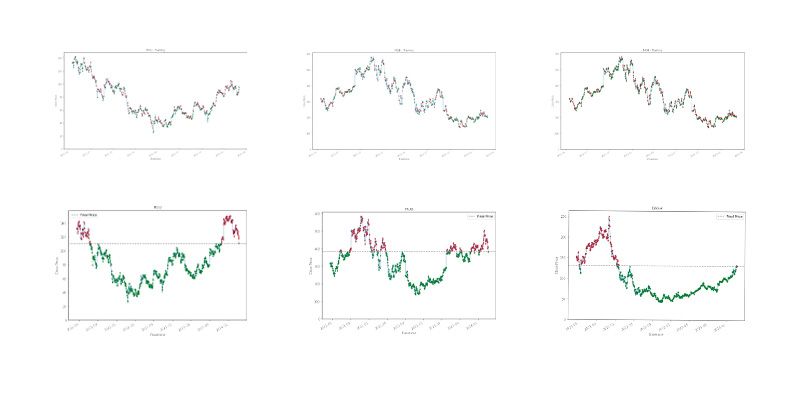
Pattern Recognition in Stock Price Volatility and Market Performance
Jan 11, 2024
machine-learning scikit-learn data-science web-scrape finance time-series-analysisAn in depth exploration of stock market data through feature engineering and pattern recognition. This study analyzes historical price changes and volatility to identify trends across diverse companies using custom statistical metrics and datetime features.
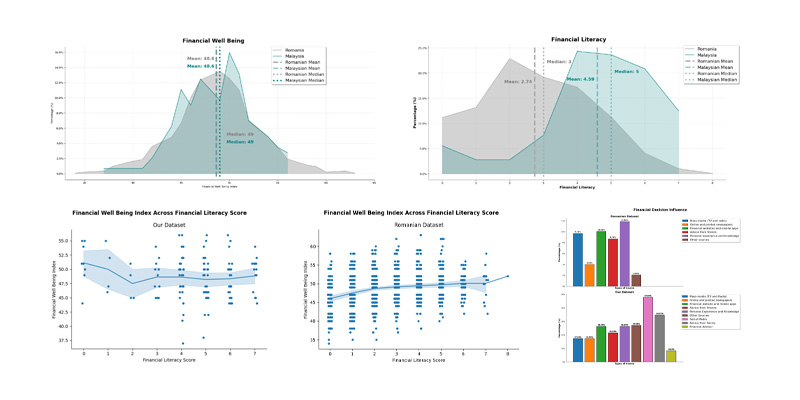
Our Malaysian Dataset (Part 1) - A Cross-Cultural Analysis with Romanian Dataset for Financial Well-Being, Literacy and Behaviour
Nov 01, 2023
python data-visualization data-analysis pandas numpy seaborn matplotlib financeWe compare the Romanian dataset with our own surveyed dataset and explore the relationship between the sociodemographic and financial behaviour, with financial well being and financial literacy.
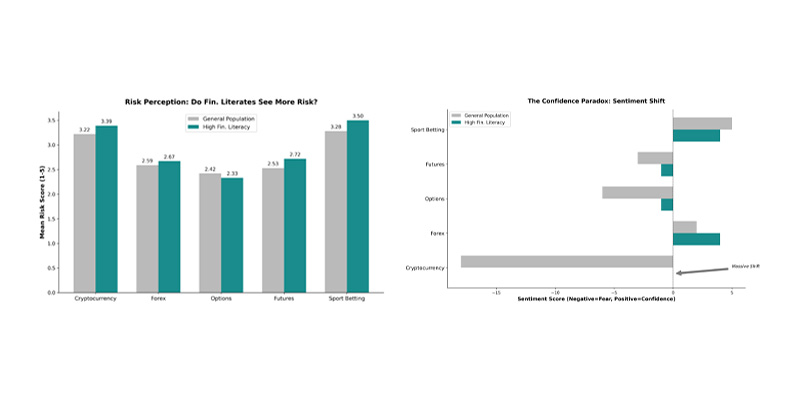
Our Malaysian Dataset (Part 2) - Financial Literacy and High Risk Financial Vehicles
Nov 01, 2023
python data-analysis finance pandasPart 2 of the analysis focuses on High Risk Financial Vehicles (HRFV), data collected with the Malaysian dataset were inspired by and referenced from a Ghanaian study. We explore how financial literacy influence perception and participation in activities like sports betting and cryptocurrency.
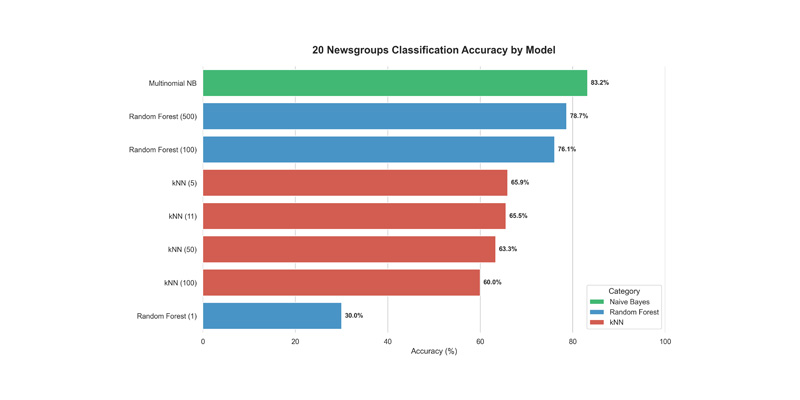
Supervised Learning Benchmarks for Numeric and Textual Data
Sep 18, 2023
machine-learning scikit-learn data-visualization classificationThis project conducts a detailed evaluation of popular machine learning algorithms and their performance characteristics. It benchmarks Naive Bayes, Random Forest, and k Nearest Neighbors across multiple datasets ranging from simple iris data to complex geospatial and text categories. The analysis explores the relationship between hyperparameter tuning and model efficiency while providing quantitative results on accuracy and execution time.
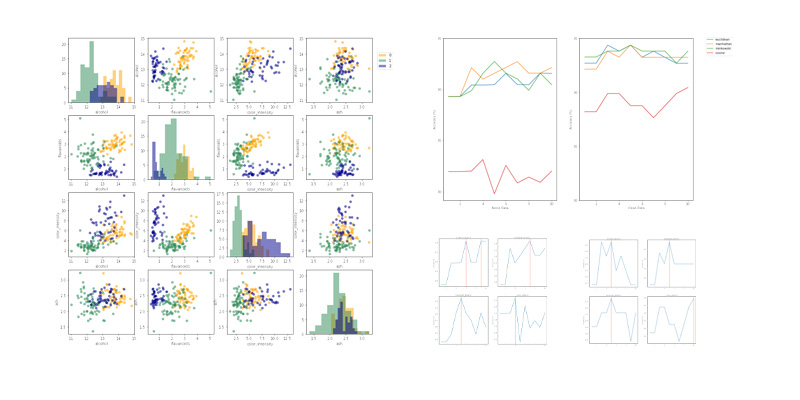
Wine Classification using k Nearest Neighbour from Scratch
Jul 17, 2023
python machine-learning clustering matplotlib seabornI created a machine learning model to categorize types of Italian wine. This project features a custom implementation of the k Nearest Neighbour algorithm. I also developed the nested cross validation logic without using external libraries. The work explores model stability when handling data with Gaussian noise.